- Solutions
- Consulting & Training
- Asset Reliability and Safety Assessments
- Preventive Maintenance Optimization
- Parts Inventory Optimization
- Work Management, Planning, and Scheduling
- CMMS/EAM Software and Integrations
- PdM and CbM Program Development
- Safety Critical Procedures
- Electrical Safety and Compliance (NFPA 70E, OSHA)
- Training Program Development and Delivery
- Inspection & Assessment
- Installation & Repair
- Electrical Maintenance and Repairs
- Electrical Retrofits and Capital Improvements
- Switchgear/Switchboard Maintenance and Upgrades
- NETA Certified Electrical Maintenance, Testing, and Repairs
- Infrastructure Advisory and Strategy
- Generators and UPS Installation
- Electrical Signage, Lighting, and Controls
- Rooftop Safety and Lightning Protection
- EV Charging Infrastructure
- Program Management
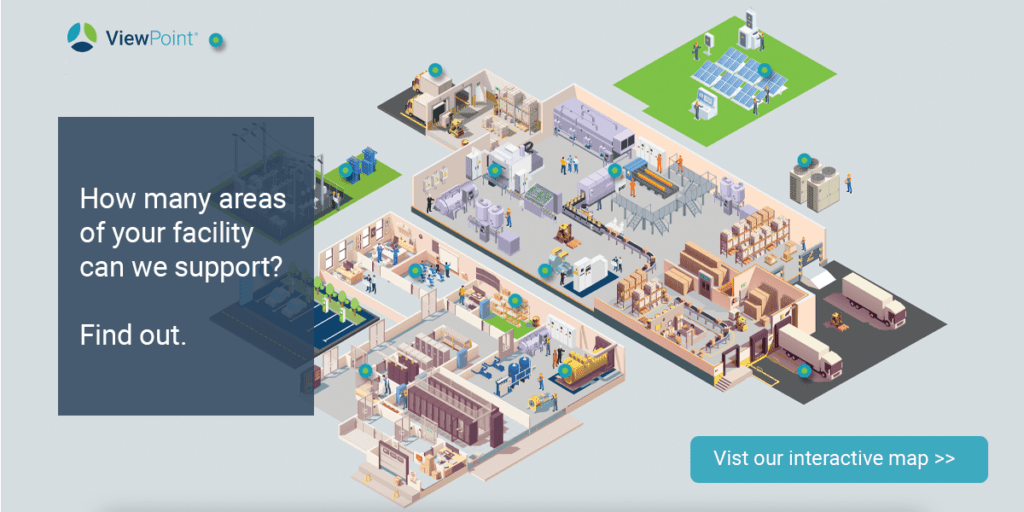
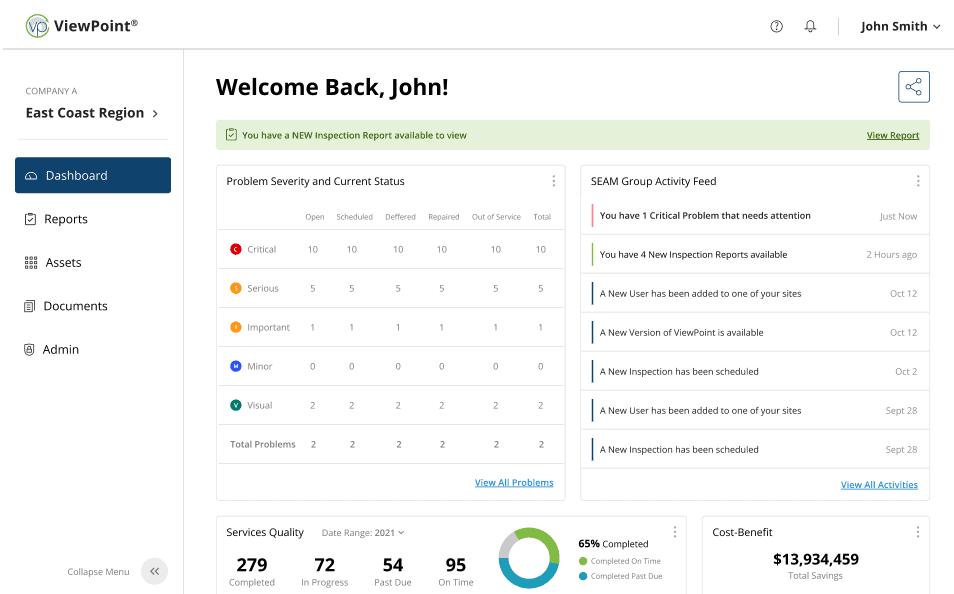
- ViewPoint ®️
Our SolutionsConsulting and TrainingInspection and AssessmentInstallation and RepairEV Charging InfrastructureProgram ManagementViewPoint ®️Our SolutionsHands-on guidance to get the most out of your safety, reliability, and maintenance capabilities.
Identify and mitigate the risks impacting your organization’s most critical electrical assets.
Ensure the reliability and ongoing maintenance of your most critical energized assets.
From site planning to service operations, we are focused on the optimal utilization of your EV infrastructure.
Drive a safer, more reliable organization with custom program management solutions.
Leverage data-driven insights to ensure the safety, reliability, and maintenance of your most critical assets.
Consulting and TrainingInspection and Assessment
Learn about the critical need for arc flash relays in your electrical switchgear
Installation and RepairEV Charging Infrastructure
Installing EV charging stations? Here are 5 questions you’ll want to consider.
Program Management
Protect your people and energized assets with a more effective Lockout/Tagout program
ViewPoint ®️
ViewPoint® empowers you with the information and clarity needed to prioritize repairs following your IR inspections.
- Consulting & Training
- Expertise
Protect your people, customers, and assets with an integrated safety approach.
Maximize the life of your assets through proactive, data-informed maintenance.
Boost uptime and maximize efficiency with a renewed focus on asset reliability.
- Learn
Access resources from our leading experts to advance the safety, maintenance, and reliability of your organization.
- About Us
Turn our expertise as a global energized asset management leader into better business outcomes.
Find out how our mission is driving change for hundreds of companies across the world.
Experience a people-first culture striving to create a safer, more reliable world.
Talk to an expert about how SEAM Group can help you build a safer, more reliable organization.Come join a company focused on motivating and mobilizing employees for success.
Meet a senior leadership team working to make a difference in our industry and beyond.
- Careers
- EN
- ViewPoint Login